I recently completed the AI Solutions on Cisco Infrastructure Essentials (DCAIE) course on Cisco U. It took me about 1 month to go through all of it and got 32 CE credits for it (Yay), but I ain’t going to bore you with the details. I just thought it would be cool to blog about my main takeaway from this course - AI Network Architecture in Data Centres.

Background
- There are two main types of AI workloads: training and inferencing (Cisco is going to say there’s more but this is my perspective anyways).
- In the training phase, we will do parameter tuning, hypermeter tuning, backpropagation learning yada yada yada. This is the phase that needs big muscle like GPUs, TPUs or even FPGAs (Basically a programmable hardware, sorta like how you would burn a DVD?).
- Thus, the network requirements of this phase are
- High bandwidth: To allow nodes to communicate with multiple nodes efficiently. This is required due to GPU limitations.
- Non-blocking lossless fabric: Packet loss allowed is 0 because any packet loss will make us retrain the AI model.
- Congestion management: Avoid dropping any packets during congestion
- In the inferencing phase, the weights of the model has been set and the goal is to “use” the AI model. As such, this phase uses way less processing power and functions more like a web service. The network requirements of this phase include your classic web service stuff like:
- Low latency: For better user experience
- Low jitter
Training Phase Network Requirements
Example Training Phase Network Architecture
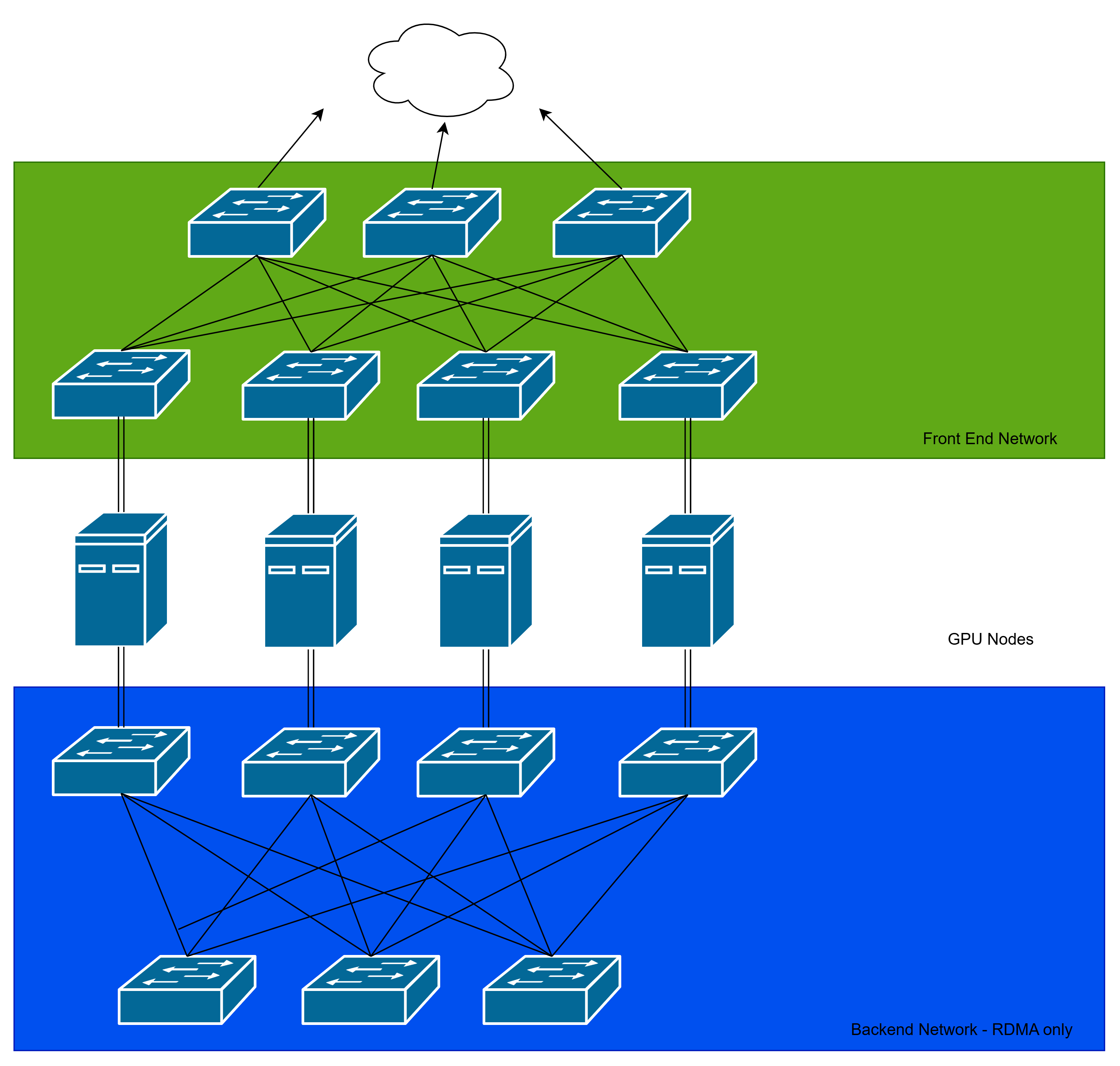
- Each node is dual-homed for redundancy and efficiency.
High Bandwidth
- An AI training network requires a high bandwidth network to support Remote Direct Memory Access (RDMA) between the GPU memory of its nodes.
- Quick tangent: It is impossible to train billion parameters model on a single GPU because it simply does not have enough memory! You don’t hear vendors selling GPUs with terabytes of memory either, right? Hyperscalers achieve this scale by connecting multiple GPUs together in a distributed computing model.
- To support distributed computing with GPU, a technology called RDMA was created. In a microprocessor (thanks Mr Emran), Direct Memory Access allows peripherals to communicate directly with memory bypassing the CPU. RDMA allows a remote GPU to communicate with the memory of another remote GPU bypassing the CPU!
- To support this,
- We use a spine-and-leaf/clos architecture to connect the nodes together. This ensures all nodes are always 3 hops away and have a dedicated link to each other.
- The spine-and-leaf architecture also allows us to load balance traffic between multiple lines. The idea is instead of maintaining data connection on one line (like in STP), we send data to all lines simultaneously. Of course, the receiving switch would have to know how to reorder the data correctly.
- In addition, we create two clos networks! The frontend network is for classic node-to-node communication while the backend network is reserved for RDMA traffic.
- We can also use special cables like Infiniband for more bandwidth. However, due to costs, people also use RDMA over Converged Ethernet (RoCE) to take advantage of Ethernet.
Non-blocking lossless fabric
- “Non-blocking” means the switch in the fabric must be able to support full capacity traffic in and out of all ports at the same time. To illustrate, let’s say I have a switch with 24 10GBps ports. It means that the switch must be able to support 240 GBps traffic in and out at the same time! Not all switches are able to do this, hence, the term “network buffer” in most switches.
- “Lossless” means that the fabric must not allow any packet drop. Nil.
- The reason we need this kind of fabric is because any dropped packets may lead to us to retrain the AI model.
- To achieve this,
- Buy non-blocking switches. I heard that the switching capacity must be two times the total bandwidth, as in, a switch with 48 10Gbps ports must support 48x10x2=960Gbps to be non-blocking.
- We can also achieve lossless with congestion avoidance techniques.
Congestion Management
- Network congestion is unavoidable, just ask anyone using UM wifi. So the question is how do we reduce and handle congestion?
- In Ethernet, there are two ways to handle congestion: Explicit Congestion Notification (ECN) and Priority Flow Control (PFC)
- Explicit Congestion Notification (ECN)
- We can set 2 thresholds on the network buffer in the switch. When the lower threshold is reached, the switch will send Congestion Encountered packets back to the low priority senders. However, when the high threshold is reached, the switch will send Congestion Encountered packets to all senders.
- ECN advises the sender to slow down the rate of sending packets.
- Note: It does not drop packets!
- Priority Flow Control (PFC):
- We can set 2 thresholds on the network buffer in the switch, XON (higher threshold) and XOFF (lower threshold). When XON is reached, the switch will send PFC to the sending switch. Only when the buffer go below XOFF threshold, the switch will stop sending PFC packets.
- This has the side effect of filling up the buffer on the sending switch.
- If the buffer of sender switch also exceeds the XON threshold, it will send PFC to the previous sending switch and so on, creating a cascading effect.
- Note: It does not drop packets!
Inference Phase Network Requirements
- In this phase, we are mainly trying to reduce latency.
- Best way to do it? Edge/Fog computing.
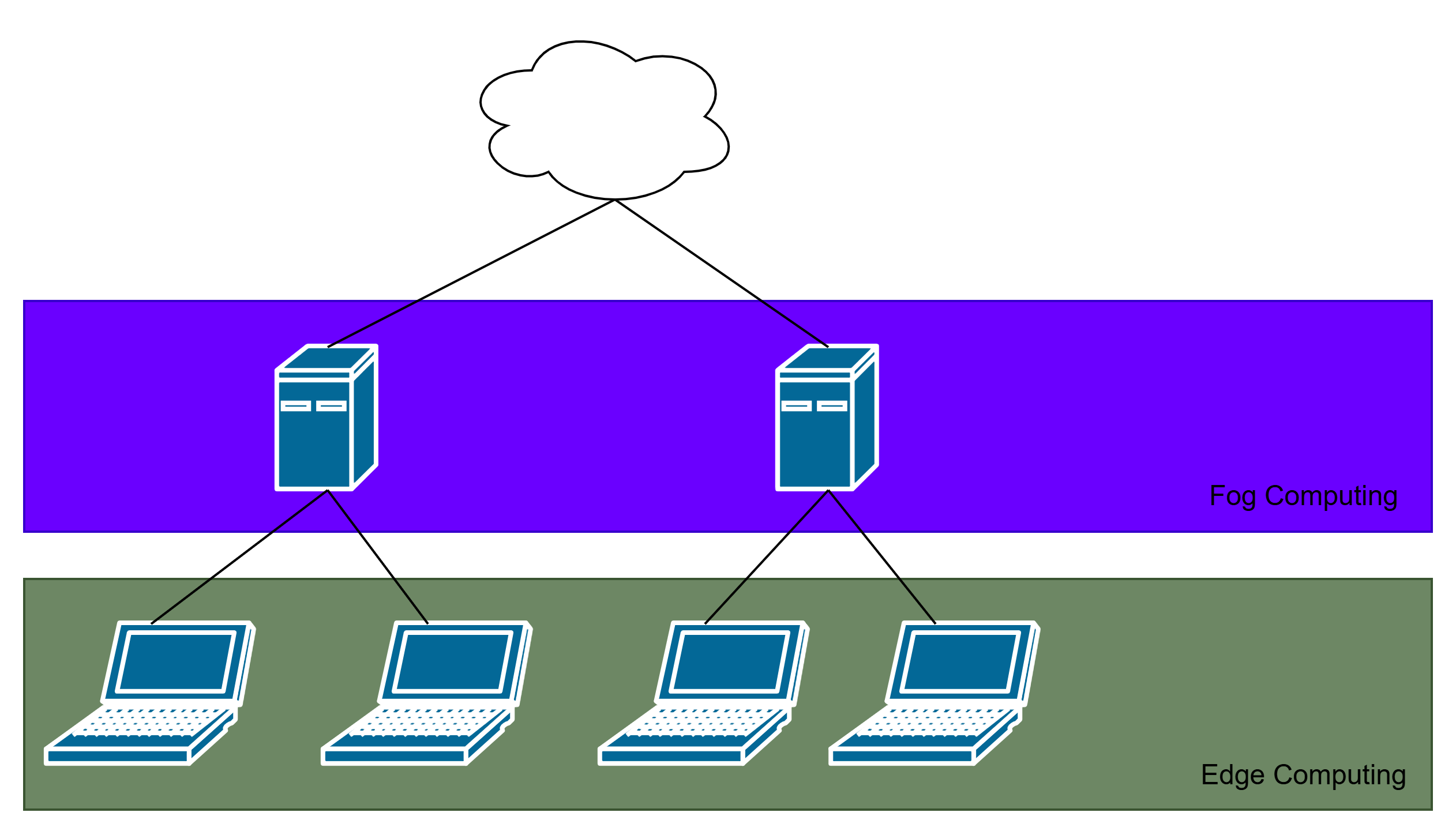
- Some models are small and light enough to be run on edge devices.
- This decreases latency and network hops required
- I guess it is what Google Chrome is doing. Cough cough.
Conclusion
This is just scratching the surface of the world of data centers. Did you know storage can be virtualized and made into a network too? The solution is left as practice for the reader. Hehe. Thanks for reading.